Guía Completa de Google Antigravity: Desde la Instalación hasta el Uso Efectivo
Category:Inteligencia Artificial,ProgramaciónIntroducción
La inteligencia artificial está transformando el desarrollo de software a una velocidad sin precedentes. Durante años, los desarrolladores trabajaron escribiendo líneas de código manualmente, consultando documentación y realizando pruebas repetitivas. Hoy estamos entrando en una nueva era: el desarrollo dirigido por agentes inteligentes.
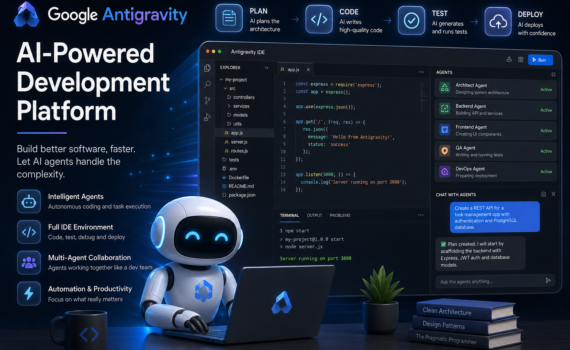
En este contexto aparece Google Antigravity, una plataforma de desarrollo basada en agentes de IA diseñada para automatizar tareas complejas de programación, planificación, pruebas, investigación y despliegue de aplicaciones. Google describe Antigravity como una plataforma de desarrollo “agent-first”, donde los agentes inteligentes se convierten en participantes activos del proceso de creación de software.
Esta guía cubre todo el ciclo de adopción de Antigravity:
- Qué es Google Antigravity
- Instalación paso a paso
- Configuración inicial
- Conceptos fundamentales
- Creación de proyectos
- Uso de agentes inteligentes
- Desarrollo de aplicaciones reales
- Automatización de tareas
- Mejores prácticas
- Casos de uso avanzados
- Estrategias para maximizar productividad
El objetivo es que al finalizar puedas utilizar Antigravity como una verdadera plataforma de desarrollo asistida por IA.
Capítulo 1: ¿Qué es Google Antigravity?
Google Antigravity es una plataforma de desarrollo impulsada por agentes inteligentes que combina:
- Entorno de desarrollo (IDE)
- Gestión de agentes autónomos
- Automatización de tareas
- Navegación web asistida
- Ejecución de pruebas
- Gestión de proyectos
- Integración con modelos de IA
A diferencia de herramientas tradicionales como Visual Studio Code, IntelliJ o Eclipse, Antigravity no se limita a ser un editor de código.
Su propuesta es diferente:
En lugar de decirle a la IA cómo programar, le dices qué quieres construir.
La plataforma puede:
- Crear proyectos completos
- Diseñar arquitectura
- Generar código
- Crear pruebas unitarias
- Corregir errores
- Revisar seguridad
- Generar documentación
- Desplegar aplicaciones
Todo ello mediante agentes inteligentes coordinados.
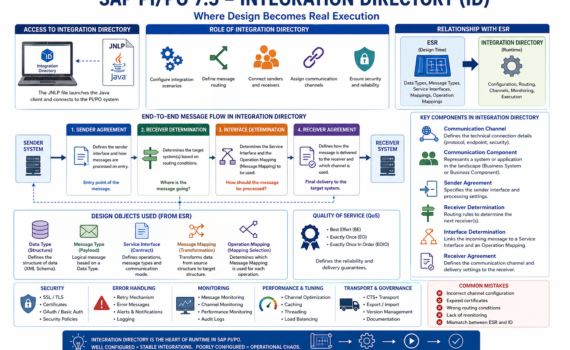
Capítulo 2: Arquitectura de Google Antigravity
Antigravity se compone de varios elementos.
1. Antigravity Platform
Es el centro de control principal.
Permite:
- Gestionar agentes
- Supervisar tareas
- Coordinar proyectos
- Ejecutar automatizaciones
2. Antigravity IDE
Es el entorno de desarrollo.
Incluye:
- Editor de código
- Explorador de archivos
- Terminal integrada
- Chat con agentes
3. Antigravity CLI
Interfaz de línea de comandos.
Ideal para:
- Automatizaciones
- Pipelines CI/CD
- Operaciones remotas
4. Antigravity SDK
Permite integrar agentes Antigravity dentro de aplicaciones externas.
Capítulo 3: Requisitos Previos
Antes de instalar Antigravity necesitarás:
Hardware recomendado
- Procesador de 4 núcleos o superior
- 16 GB RAM
- SSD de al menos 20 GB libres
Sistemas Operativos compatibles
- Windows 10 / 11
- macOS
- Algunas distribuciones Linux
Software requerido
- Navegador Chrome
- Cuenta Google
- Conexión a Internet estable
Google recomienda utilizar una cuenta Gmail para aprovechar completamente las funciones de autenticación y sincronización.
Capítulo 4: Descarga e Instalación
Paso 1: Descargar Antigravity
Dirígete al portal oficial:
Selecciona tu sistema operativo.
Descarga:
- Windows Installer
- macOS Package
- Linux Package
Paso 2: Ejecutar el instalador
Al iniciar el instalador aparecerá el asistente de instalación.
Selecciona:
- Idioma
- Carpeta de instalación
- Componentes opcionales
Paso 3: Inicio de sesión
Una vez instalada la aplicación:
- Inicia Antigravity.
- Inicia sesión con Google.
- Autoriza los permisos solicitados.
La plataforma quedará vinculada a tu cuenta.
Capítulo 5: Configuración Inicial
Durante el primer inicio encontrarás varias opciones.
Tema visual
Puedes elegir:
- Light
- Dark
Modo de trabajo con agentes
Agent-Driven Development
La IA realiza casi todo.
Ideal para:
- Prototipos rápidos
- MVPs
Agent-Assisted Development
La IA ayuda mientras el desarrollador dirige.
Recomendado para la mayoría de usuarios.
Review-Driven Development
Cada acción requiere aprobación humana.
Ideal para:
- Sistemas críticos
- Ambientes corporativos
Capítulo 6: Conociendo la Interfaz
La interfaz se divide en varios componentes.
Workspace
Área principal del proyecto.
Contiene:
- Archivos
- Carpetas
- Configuración
Agent Panel
Chat con agentes.
Desde aquí das instrucciones.
Ejemplo:
Crear una API REST en Spring Boot para gestionar clientes.El agente analizará el requerimiento y comenzará a trabajar.
Terminal
Permite:
- Ejecutar comandos
- Instalar dependencias
- Lanzar pruebas
Preview
Vista previa de aplicaciones web.
Capítulo 7: Primer Proyecto
Vamos a crear una aplicación simple.
Crear carpeta
MiPrimerProyectoAbrir carpeta
Selecciona:
Open FolderSolicitar código
En el panel del agente escribe:
Crear una aplicación Python que muestre Hello World.El agente:
- Creará archivos
- Escribirá código
- Generará estructura
Automáticamente.
Capítulo 8: Cómo Pensar en Prompts
La calidad de los resultados depende de tus instrucciones.
Prompt pobre
Haz una web.Prompt bueno
Crea una aplicación web para gestión de tareas usando React,
Node.js y PostgreSQL.
Debe permitir:
- Registro de usuarios
- Login
- CRUD de tareas
- Dashboard responsiveMientras más contexto proporciones, mejores serán los resultados.
Capítulo 9: Ciclo de Desarrollo con Antigravity
Un flujo típico es:
1. Definir objetivo
Crear marketplace de cursos online2. Planificación
El agente genera:
- Arquitectura
- Componentes
- Roadmap
3. Implementación
Genera:
- Backend
- Frontend
- Base de datos
4. Testing
Crea:
- Unit tests
- Integration tests
5. Correcciones
Detecta errores.
6. Deploy
Genera scripts de despliegue.
Capítulo 10: Uso de Múltiples Agentes
Una de las capacidades más potentes es trabajar con varios agentes simultáneamente.
Por ejemplo:
Agente 1
Arquitecto
Agente 2
Desarrollador Backend
Agente 3
Desarrollador Frontend
Agente 4
QA
Cada uno ejecuta tareas especializadas.
Capítulo 11: Desarrollo de Aplicaciones Java
Dado que muchos desarrolladores empresariales trabajan con Java, este es un caso de uso frecuente.
Prompt:
Crear sistema CRM usando:
- Java 21
- Spring Boot
- PostgreSQL
- JWT
- Swagger
- DockerAntigravity puede:
- Crear entidades
- Crear controladores
- Configurar seguridad
- Generar documentación
Reduciendo semanas de trabajo a horas.
Capítulo 12: Desarrollo SAP
Un uso interesante para profesionales SAP.
Puedes solicitar:
Generar integración SAP Integration Suite con API REST externa.o
Crear servicio OData ABAP para gestión de clientes.Los agentes pueden producir:
- Código ABAP
- Flujos CPI
- Especificaciones técnicas
Capítulo 13: Navegación Autónoma
Antigravity incorpora capacidades de navegación web.
Los agentes pueden:
- Investigar documentación
- Analizar APIs
- Comparar tecnologías
Todo sin abandonar el entorno.
Capítulo 14: Automatización de Pruebas
Ejemplo:
Genera pruebas unitarias para este proyecto.El sistema:
- Analiza el código
- Identifica funciones
- Genera casos de prueba
Posteriormente:
Ejecuta todas las pruebas.Capítulo 15: Refactorización Inteligente
Uno de los usos más rentables.
Prompt:
Refactoriza este proyecto siguiendo Clean Architecture.Resultados:
- Menor deuda técnica
- Código más mantenible
- Mejor rendimiento
Capítulo 16: Generación de Documentación
Antigravity puede generar:
- README
- Diagramas
- Documentación técnica
- Manuales de usuario
Ejemplo:
Genera documentación para desarrolladores.Capítulo 17: Casos de Uso Empresariales
ERP
Automatización de módulos.
CRM
Creación rápida de sistemas de clientes.
Integración
Conexión entre plataformas.
Data Analytics
Construcción de pipelines.
Automatización
Bots empresariales.
Capítulo 18: Mejores Prácticas
Define objetivos claros
Mal:
Haz algo útil.Bien:
Construye una aplicación de reservas para restaurantes.Divide proyectos grandes
En lugar de:
Construye un ERP completo.Usa:
- Módulo clientes
- Módulo ventas
- Módulo inventario
Revisa resultados
La IA acelera.
El criterio humano sigue siendo indispensable.
Capítulo 19: Errores Comunes
Confiar ciegamente
Siempre valida.
Prompts ambiguos
Generan resultados ambiguos.
No revisar seguridad
Especialmente en aplicaciones empresariales.
No usar control de versiones
Git sigue siendo obligatorio.
Capítulo 20: Estrategia para Ser Altamente Productivo
Los usuarios más productivos no utilizan Antigravity como un simple generador de código.
Lo utilizan como:
Arquitecto
Diseña la solución.Investigador
Compara tecnologías.Programador
Implementa funcionalidad.Tester
Genera pruebas.Documentador
Crea manuales.DevOps
Genera Dockerfiles y pipelines.De esta manera un solo desarrollador puede operar con la capacidad productiva de un pequeño equipo.
Conclusión
Google Antigravity representa una evolución importante en la forma de construir software. Más que un IDE, es una plataforma donde agentes inteligentes colaboran con los desarrolladores para planificar, implementar, probar y mantener aplicaciones completas. Su enfoque “agent-first” permite reducir significativamente el tiempo dedicado a tareas repetitivas y concentrarse en la estrategia, la arquitectura y el valor de negocio.
Para obtener resultados sobresalientes, la clave no está únicamente en la tecnología, sino en aprender a dirigirla correctamente: definir objetivos claros, proporcionar contexto suficiente y supervisar los resultados. Quienes desarrollen esa habilidad tendrán una ventaja competitiva importante en la próxima generación del desarrollo de software asistido por IA.